LLM do Zero em Go: como máquinas leem texto
E aí, pessoal!
Esta é a primeira parte de uma série chamada LLM do Zero em Go. A proposta é simples: construir um modelo de linguagem do zero, em Go, sem nenhuma biblioteca externa de machine learning. Nada de PyTorch, nada de HuggingFace, nada de wrappers prontos. Só Go puro.
A série acompanha os vídeos do canal que cobrem: o que é um LLM, como o computador representa texto, como implementar um tokenizador simples, e como implementar o BPE (Byte Pair Encoding). Este post cobre os vídeos 01 ao 04.
Hoje o foco é o problema que ninguém explica direito antes de jogar você no meio das redes neurais: como um computador lê texto, e por que isso importa tanto pra construir um LLM.
O que é um LLM de verdade
Antes de qualquer código, vale ter um modelo mental claro do que é um Large Language Model.
Um LLM não é um banco de dados de respostas. Não é uma busca. É um modelo matemático que, dado um contexto de tokens anteriores, calcula a probabilidade de cada token possível ser o próximo.
Isso é tudo. A operação central é:
1
P(próximo_token | tokens_anteriores)
Internamente, essa operação acontece através de matrizes de números de ponto flutuante. O texto de entrada é convertido em vetores numéricos, esses vetores passam por camadas de transformações (multiplicações de matrizes, funções de ativação, atenção), e na saída temos uma distribuição de probabilidade sobre o vocabulário.
A geração de texto é autoregressiva: o modelo gera um token, esse token entra de volta como contexto, o modelo gera o próximo, e assim por diante.
1
2
3
4
5
6
7
8
9
10
Entrada: "O gato"
Modelo calcula: P("subiu" | "O gato") = 0.31
P("dormiu" | "O gato") = 0.28
P("comeu" | "O gato") = 0.19
...
Saída escolhida: "subiu"
Nova entrada: "O gato subiu"
Modelo calcula: P("no" | "O gato subiu") = 0.45
...
Para que tudo isso funcione, o texto precisa virar números. É aí que entra a tokenização.
Como o computador vê texto
Antes de falar em tokens, precisa entender como o computador representa texto no nível mais baixo.
Bits e bytes
Um computador só entende bits: 0 ou 1. Agrupamos 8 bits em um byte. Um byte pode representar 256 valores distintos (0 a 255).
Um caractere, portanto, precisa ser mapeado para um ou mais bytes. Como fazemos esse mapeamento é o problema do encoding.
ASCII: o começo
O ASCII (American Standard Code for Information Interchange) foi criado nos anos 60. Ele define 128 caracteres usando 7 bits. Os primeiros 32 são caracteres de controle (newline, tab, etc). Os demais são letras do alfabeto inglês, dígitos e pontuação.
1
2
3
4
5
6
7
Caractere | Decimal | Binário
----------+---------+---------
'A' | 65 | 01000001
'B' | 66 | 01000010
'a' | 97 | 01100001
'0' | 48 | 00110000
' ' | 32 | 00100000
Isso funciona bem para inglês. Mas e o ‘ã’ com acento? O ‘ç’ cedilha? O ASCII não tem esses caracteres.
Latin-1 e o caos de encodings
Surgiram dezenas de encodings diferentes para cobrir outros idiomas. Latin-1 (ISO-8859-1) usa o byte completo (256 valores) e adiciona caracteres europeus ocidentais nos valores de 128 a 255. Windows criou o CP-1252. Outros sistemas criaram outros esquemas.
O resultado: o mesmo byte podia significar caracteres diferentes dependendo do encoding que você assumia. Abrir um arquivo de texto com o encoding errado gerava aquelas sequências de caracteres ilegíveis que todo desenvolvedor já viu.
UTF-8: o encoding que ganhou
O UTF-8 resolveu o problema de forma elegante. Ele pode representar qualquer caractere Unicode (mais de 1,1 milhão de caracteres), e faz isso com tamanho variável: de 1 a 4 bytes por caractere.
A regra de codificação:
1
2
3
4
5
6
Unicode range | Bytes | Formato binário
--------------------+-------+------------------------------------------
U+0000 - U+007F | 1 | 0xxxxxxx
U+0080 - U+07FF | 2 | 110xxxxx 10xxxxxx
U+0800 - U+FFFF | 3 | 1110xxxx 10xxxxxx 10xxxxxx
U+10000 - U+10FFFF | 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Os caracteres ASCII (0-127) são representados com exatamente 1 byte, e esse byte é idêntico ao ASCII original. Isso garante compatibilidade retroativa.
Um exemplo prático com a letra ‘a’ e o ‘ã’ com acento:
1
2
'a' -> U+0061 -> 1 byte: 0x61 (97 em decimal)
'ã' -> U+00E3 -> 2 bytes: 0xC3 0xA3 (195, 163 em decimal)
Já a letra chinesa ‘中’:
1
'中' -> U+4E2D -> 3 bytes: 0xE4 0xB8 0xAD
Go e strings: o que você precisa saber
Go tem uma relação específica com texto que pega muita gente de surpresa.
Em Go, uma string é uma sequência de bytes imutável. Não é uma sequência de caracteres. Bytes.
Isso tem consequências diretas:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
package main
import "fmt"
func main() {
s := "Olá"
// len() conta bytes, não caracteres
fmt.Println(len("hello")) // 5
fmt.Println(len("Olá")) // 5 (o 'á' com acento usa 2 bytes)
// indexação acessa bytes
fmt.Printf("%x\n", s[0]) // 4f ('O')
fmt.Printf("%x\n", s[2]) // c3 (primeiro byte do 'á')
fmt.Printf("%x\n", s[3]) // a1 (segundo byte do 'á'))
// range itera sobre runes (codepoints Unicode)
for i, r := range s {
fmt.Printf("índice %d: %c (U+%04X)\n", i, r, r)
}
}
Saída:
1
2
3
4
5
6
7
8
5
5
4f
c3
a1
índice 0: O (U+004F)
índice 2: l (U+006C)
índice 3: á (U+00E1)
Repare: o range pula do índice 2 para o 3. O índice 2 é ‘l’, que ocupa 1 byte. O índice 3 é ‘á’, que ocupa 2 bytes. Por isso o próximo seria índice 5.
O tipo rune em Go é um alias para int32, e representa um codepoint Unicode. Quando você precisa trabalhar com caracteres (não bytes), você usa rune.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "Olá, 世界"
fmt.Println("Bytes:", len(s))
fmt.Println("Runes:", utf8.RuneCountInString(s))
// Convertendo para slice de runes
runes := []rune(s)
fmt.Println("Terceiro caractere:", string(runes[2]))
}
Saída:
1
2
3
Bytes: 13
Runes: 8
Terceiro caractere: á
Essa diferença entre bytes e runes é fundamental quando construímos um tokenizador. Dependendo de como você itera a string, você obtém resultados completamente diferentes.
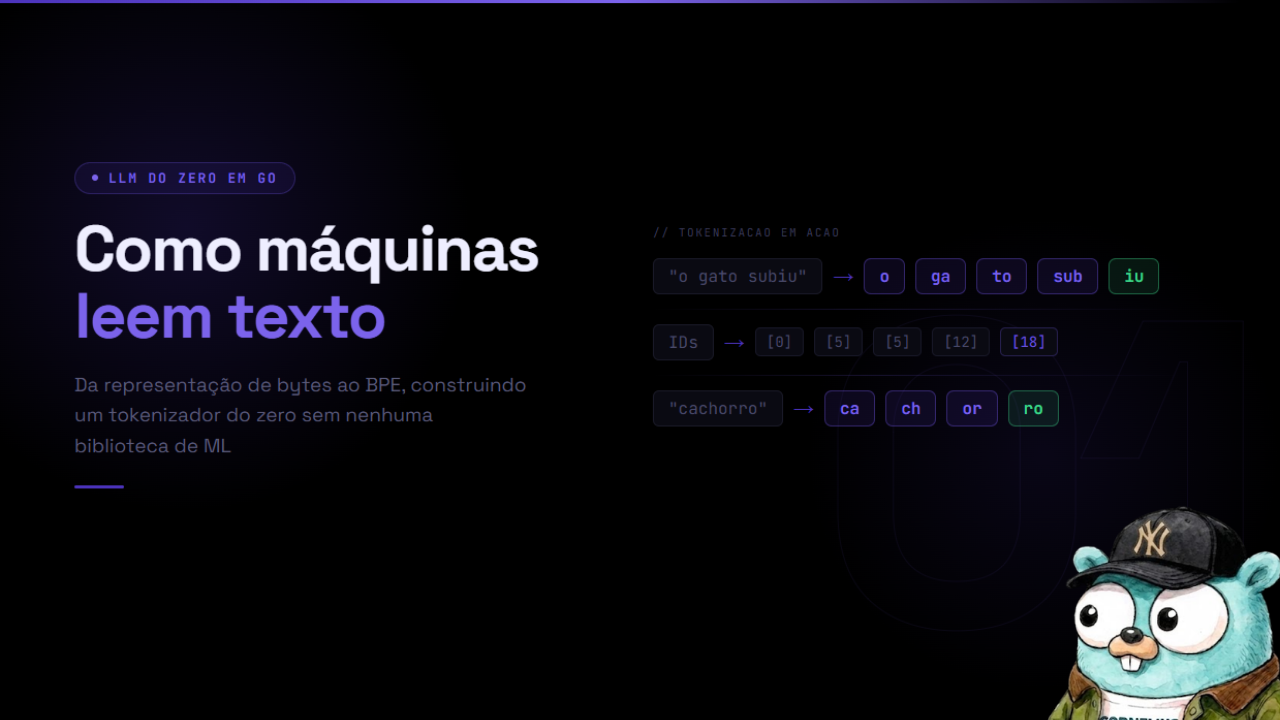
Por que precisamos de tokens
Um LLM opera sobre números. Matrizes de floats, multiplicações lineares, funções de ativação. Texto puro não entra diretamente nesses cálculos.
Precisamos de uma função que converta texto em sequências de inteiros, e outra que converta de volta. Esse processo é a tokenização.
O conceito central é o vocabulário: um conjunto fixo de tokens, cada um com um ID numérico único. Durante o treinamento, o modelo aprende um vetor de representação (embedding) para cada ID no vocabulário. Durante a inferência, o texto de entrada é convertido em IDs, os IDs viram vetores, e os cálculos acontecem nesses vetores.
A escolha de como definir o vocabulário é o que diferencia as estratégias de tokenização. E essa escolha tem impacto direto no tamanho do modelo, na qualidade do treinamento e na capacidade de lidar com palavras novas.
Vamos implementar a interface que todos os nossos tokenizadores vão seguir:
1
2
3
4
5
6
type Tokenizer interface {
Train(corpus string, vocabSize int)
Encode(text string) []int
Decode(ids []int) string
VocabSize() int
}
Train constrói o vocabulário a partir de um corpus. Encode converte texto em IDs. Decode converte IDs de volta em texto. VocabSize retorna quantos tokens existem no vocabulário.
Tokenizador simples por palavras
A abordagem mais intuitiva: cada palavra é um token.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
package tokenizer
import (
"sort"
"strings"
)
type WordTokenizer struct {
vocab map[string]int
reverse map[int]string
}
func (t *WordTokenizer) Train(corpus string, vocabSize int) {
words := strings.Fields(corpus)
freq := make(map[string]int)
for _, w := range words {
freq[strings.ToLower(w)]++
}
type entry struct {
word string
count int
}
var entries []entry
for w, c := range freq {
entries = append(entries, entry{w, c})
}
sort.Slice(entries, func(i, j int) bool {
return entries[i].count > entries[j].count
})
t.vocab = make(map[string]int)
t.reverse = make(map[int]string)
for i, e := range entries {
if i >= vocabSize {
break
}
t.vocab[e.word] = i
t.reverse[i] = e.word
}
}
func (t *WordTokenizer) Encode(text string) []int {
words := strings.Fields(strings.ToLower(text))
ids := make([]int, 0, len(words))
for _, w := range words {
if id, ok := t.vocab[w]; ok {
ids = append(ids, id)
} else {
ids = append(ids, -1) // token desconhecido
}
}
return ids
}
func (t *WordTokenizer) Decode(ids []int) string {
words := make([]string, 0, len(ids))
for _, id := range ids {
if w, ok := t.reverse[id]; ok {
words = append(words, w)
} else {
words = append(words, "<unk>")
}
}
return strings.Join(words, " ")
}
func (t *WordTokenizer) VocabSize() int {
return len(t.vocab)
}
Usando o tokenizador:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package main
import (
"fmt"
"tokenizer"
)
func main() {
corpus := `o gato subiu no telhado o gato desceu o cachorro latiu
o gato correu o cachorro também correu o gato ganhou`
tok := &tokenizer.WordTokenizer{}
tok.Train(corpus, 10)
ids := tok.Encode("o gato correu")
fmt.Println("IDs:", ids)
fmt.Println("Decode:", tok.Decode(ids))
ids2 := tok.Encode("o pato voou")
fmt.Println("IDs com desconhecido:", ids2)
fmt.Println("Decode:", tok.Decode(ids2))
}
Saída:
1
2
3
4
IDs: [0 1 5]
Decode: o gato correu
IDs com desconhecido: [0 -1 -1]
Decode: o <unk> <unk>
O problema do OOV
“pato” e “voou” não estavam no corpus de treinamento. Eles são tokens OOV (Out Of Vocabulary). O tokenizador por palavras não sabe o que fazer com eles, então retorna -1.
Isso é um problema sério. Nomes próprios, termos técnicos, palavras em outros idiomas, erros de digitação: tudo isso vai virar <unk>. O modelo perde informação sobre o que estava no texto.
Além disso, o vocabulário de palavras cresce muito rápido. O português tem centenas de milhares de palavras. Um vocabulário grande significa uma camada de embedding enorme, o que aumenta o custo computacional e dificulta o treinamento.
BPE: Byte Pair Encoding
O BPE resolve o problema do OOV de forma esperta. Em vez de trabalhar no nível de palavras, ele começa no nível de bytes (ou caracteres) e aprende progressivamente quais sequências merecem virar tokens próprios.
A ideia central
- Comece com cada byte como um token individual. Isso garante que qualquer texto pode ser representado.
- Conte os pares de tokens adjacentes mais frequentes no corpus.
- Mescle o par mais frequente em um novo token.
- Repita até atingir o tamanho de vocabulário desejado.
Implementação do núcleo do BPE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
package tokenizer
type BPE struct {
vocab map[string]int
merges [][2]string
}
func (b *BPE) Train(corpus string, vocabSize int) {
b.vocab = make(map[string]int)
b.merges = nil
// Vocabulário base: todos os bytes únicos
for i := 0; i < 256; i++ {
b.vocab[string([]byte{byte(i)})] = i
}
// Representar o corpus como sequência de símbolos (um byte cada)
symbols := make([][]byte, 0, len(corpus))
for _, r := range []byte(corpus) {
symbols = append(symbols, []byte{r})
}
for len(b.vocab) < vocabSize {
// Contar todos os pares adjacentes
pairs := make(map[[2]string]int)
for i := 0; i < len(symbols)-1; i++ {
pair := [2]string{string(symbols[i]), string(symbols[i+1])}
pairs[pair]++
}
if len(pairs) == 0 {
break
}
// Encontrar o par mais frequente
var best [2]string
bestCount := 0
for pair, count := range pairs {
if count > bestCount {
best = pair
bestCount = count
}
}
// Criar novo token pela mesclagem
merged := best[0] + best[1]
b.merges = append(b.merges, best)
b.vocab[merged] = len(b.vocab)
// Aplicar a mesclagem em todo o corpus
newSymbols := make([][]byte, 0, len(symbols))
for i := 0; i < len(symbols); i++ {
if i < len(symbols)-1 &&
string(symbols[i]) == best[0] &&
string(symbols[i+1]) == best[1] {
newSymbols = append(newSymbols, []byte(merged))
i++ // pula o próximo, já foi incorporado
} else {
newSymbols = append(newSymbols, symbols[i])
}
}
symbols = newSymbols
}
}
func (b *BPE) Encode(text string) []int {
// Começar com bytes individuais
symbols := make([]string, 0, len(text))
for _, bt := range []byte(text) {
symbols = append(symbols, string([]byte{bt}))
}
// Aplicar as mesclagens na ordem em que foram aprendidas
for _, merge := range b.merges {
merged := merge[0] + merge[1]
newSymbols := make([]string, 0, len(symbols))
for i := 0; i < len(symbols); i++ {
if i < len(symbols)-1 &&
symbols[i] == merge[0] &&
symbols[i+1] == merge[1] {
newSymbols = append(newSymbols, merged)
i++
} else {
newSymbols = append(newSymbols, symbols[i])
}
}
symbols = newSymbols
}
ids := make([]int, 0, len(symbols))
for _, s := range symbols {
if id, ok := b.vocab[s]; ok {
ids = append(ids, id)
}
}
return ids
}
func (b *BPE) Decode(ids []int) string {
reverse := make(map[int]string, len(b.vocab))
for s, id := range b.vocab {
reverse[id] = s
}
result := make([]byte, 0)
for _, id := range ids {
if s, ok := reverse[id]; ok {
result = append(result, []byte(s)...)
}
}
return string(result)
}
func (b *BPE) VocabSize() int {
return len(b.vocab)
}
Rodando o BPE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
package main
import (
"fmt"
"tokenizer"
)
func main() {
corpus := `o gato subiu no telhado o gato desceu
o cachorro latiu o gato correu o cachorro
também correu o gato ganhou o cachorro perdeu`
bpe := &tokenizer.BPE{}
bpe.Train(corpus, 300)
fmt.Println("Vocabulário:", bpe.VocabSize(), "tokens")
text := "o gato"
ids := bpe.Encode(text)
fmt.Printf("Encode(%q): %v\n", text, ids)
fmt.Printf("Decode: %q\n", bpe.Decode(ids))
// Palavra que não estava no corpus
text2 := "pato"
ids2 := bpe.Encode(text2)
fmt.Printf("Encode(%q): %v\n", text2, ids2)
fmt.Printf("Decode: %q\n", bpe.Decode(ids2))
}
Saída aproximada:
1
2
3
4
5
Vocabulário: 300 tokens
Encode("o gato"): [111 32 103 257 111]
Decode: "o gato"
Encode("pato"): [112 257 111]
Decode: "pato"
Repare: “pato” não estava no corpus, mas o BPE consegue codificá-la usando porções menores que ele conhece. Não há OOV. No pior caso, cada byte vira um token separado, mas a decodificação continua funcionando e o texto original é recuperado perfeitamente.
Comparando as abordagens
| Critério | Tokenizador por palavras | BPE |
|---|---|---|
| Tamanho do vocabulário | Muito grande | Controlado (configurável) |
| Palavras fora do vocab | Vira <unk> | Decomposta em subunidades |
| Palavras compostas | Um token | Pode ser vários tokens |
| Idiomas misturados | Problemático | Funciona bem |
| Palavras raras | Raramente treinadas | Partes reutilizadas |
| Implementação | Simples | Mais complexo |
| Compressão do texto | Alta (1 token/palavra) | Média |
O BPE é o algoritmo base do GPT-2 e GPT-3. O tokenizador do GPT-4 (chamado cl100k_base) usa uma variante chamada BBPE (Byte-level BPE) com algumas regras adicionais de pré-tokenização. O SentencePiece, usado pelo LLaMA e T5, implementa tanto BPE quanto unigram language model.
Para a nossa série, o BPE é a escolha certa. Vocabulário controlado, sem OOV, implementação compreensível, e compatível com o que os modelos modernos usam.
O que construímos
Neste post, partimos do nível mais baixo possível: bits, bytes, e como o UTF-8 organiza caracteres em bytes de tamanho variável. Passamos pelas peculiaridades de strings em Go (len vs range, byte vs rune), entendemos por que tokenização é necessária, implementamos um tokenizador por palavras e vimos seu problema fundamental, e implementamos o BPE do zero em Go.
O código é direto. Sem abstrações desnecessárias, sem dependências externas. Tudo em Go puro.
No próximo post da série, vamos transformar os IDs que o BPE gera em vetores de representação densos: os embeddings. É aí que o modelo começa a aprender o que os tokens significam em relação uns aos outros.