Cadeia de Markov: o primeiro modelo preditivo e seus limites
E aí, pessoal!
Este é o terceiro post da série LLM do Zero em Go. Nos posts anteriores construímos um tokenizador BPE do zero (post 1) e implementamos vetores de palavras com busca semântica (post 2). Este post cobre os vídeos 08 e 09 da série.
Antes das redes neurais dominarem o processamento de linguagem natural, as Cadeias de Markov eram a principal ferramenta para geração de texto. Entendê-las não é apenas contexto histórico: elas expõem com precisão por que precisamos de modelos mais potentes. E implementar uma em Go leva cerca de 80 linhas de código.
O que é uma Cadeia de Markov
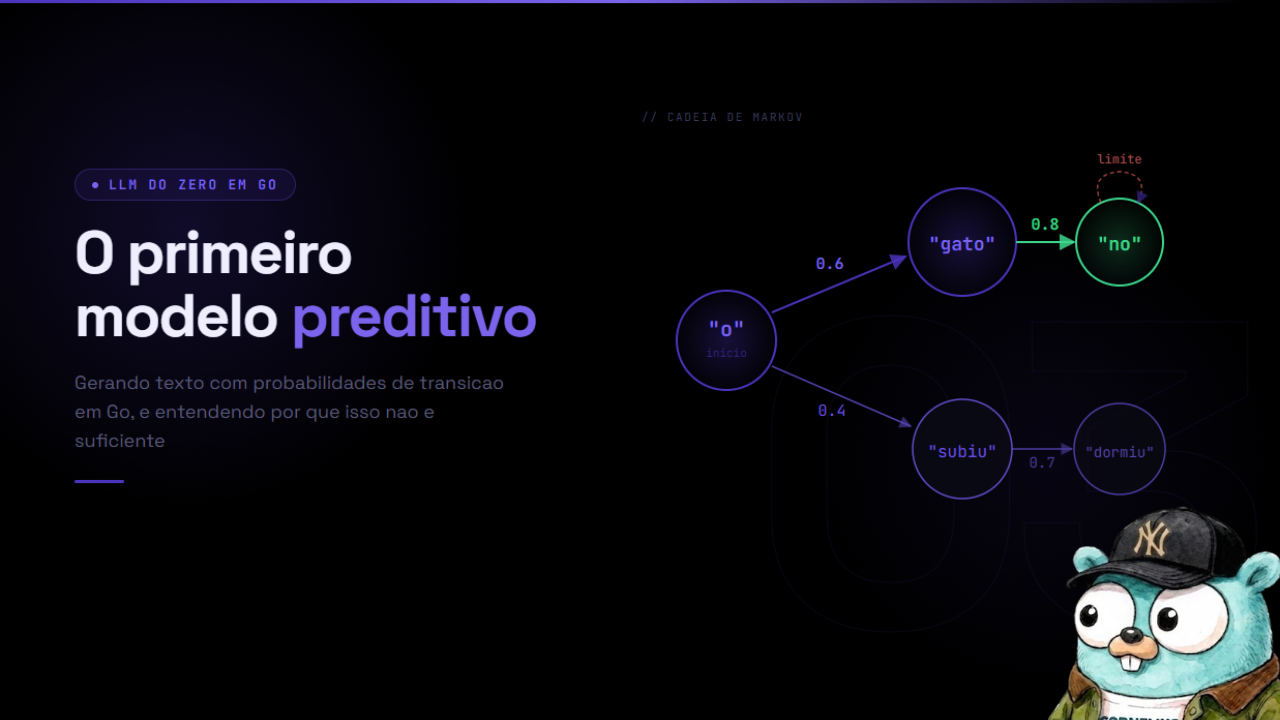
Uma Cadeia de Markov é um modelo probabilístico onde o próximo estado depende apenas do estado atual, e não de nenhuma história anterior. Essa é a propriedade de Markov.
Formalmente: dado o estado atual s_t, a probabilidade do próximo estado s_{t+1} é:
1
P(s_{t+1} | s_t, s_{t-1}, ..., s_1) = P(s_{t+1} | s_t)
Para texto, isso significa: dado um conjunto de palavras recentes, qual palavra é mais provável de vir a seguir? O modelo não sabe nada sobre o que veio antes da janela atual.
A matriz de transição
O núcleo de uma Cadeia de Markov é a tabela de transições. Cada entrada representa: “quando o estado atual é X, qual a probabilidade de o próximo ser Y?”
Considere o corpus simplificado:
1
2
3
o gato comeu o peixe
o gato dormiu
o cachorro comeu o osso
Para uma cadeia de ordem 1 (um único token como estado), a tabela de transições parcial fica:
1
2
3
4
5
6
7
8
9
Estado atual | Próximo | Contagem | Probabilidade
--------------+----------+----------+---------------
"o" | "gato" | 2 | 0.40
"o" | "peixe" | 1 | 0.20
"o" | "cachorro"| 1 | 0.20
"o" | "osso" | 1 | 0.20
"gato" | "comeu" | 1 | 0.50
"gato" | "dormiu" | 1 | 0.50
"comeu" | "o" | 2 | 1.00
Para gerar texto: começa em um estado, amostra o próximo token de acordo com as probabilidades, aquele token vira o novo estado, repete.
Ordem 1 vs. ordem 2
A ordem da cadeia define quantos tokens formam o estado:
- Ordem 1 (unigrama): o estado é uma única palavra. O contexto é mínimo.
- Ordem 2 (bigrama): o estado são duas palavras consecutivas. O texto gerado é mais coerente localmente.
- Ordem 3 (trigrama): o estado são três palavras. Ainda mais coerente, mas o espaço de estados explode.
Com ordem 2, o estado ("gato", "comeu") leva a transições diferentes do que o estado ("cachorro", "comeu"). A cadeia consegue distinguir contextos que a ordem 1 não consegue.
Implementação em Go
Vamos implementar uma Cadeia de Markov de ordem configurável em Go puro. A estrutura é simples: um mapa de estado (string de N tokens) para contagens de próximos tokens.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
package main
import (
"bufio"
"fmt"
"math/rand"
"os"
"strings"
)
// MarkovChain armazena probabilidades de transição como mapa de estado para contagens do próximo token.
type MarkovChain struct {
order int
transitions map[string]map[string]int
totals map[string]int
}
func NewMarkovChain(order int) *MarkovChain {
return &MarkovChain{
order: order,
transitions: make(map[string]map[string]int),
totals: make(map[string]int),
}
}
// key retorna uma chave string a partir de um slice de tokens.
func key(tokens []string) string {
return strings.Join(tokens, " ")
}
// Train constrói a tabela de transições a partir de um corpus de tokens.
func (m *MarkovChain) Train(tokens []string) {
for i := 0; i+m.order < len(tokens); i++ {
state := key(tokens[i : i+m.order])
next := tokens[i+m.order]
if m.transitions[state] == nil {
m.transitions[state] = make(map[string]int)
}
m.transitions[state][next]++
m.totals[state]++
}
}
// NextWord amostra o próximo token dado o estado atual.
func (m *MarkovChain) NextWord(state string) (string, bool) {
counts, ok := m.transitions[state]
if !ok {
return "", false
}
total := m.totals[state]
r := rand.Intn(total)
var cumulative int
for word, count := range counts {
cumulative += count
if r < cumulative {
return word, true
}
}
return "", false
}
// Generate produz até maxWords tokens a partir de uma semente.
func (m *MarkovChain) Generate(seed []string, maxWords int) []string {
result := make([]string, 0, len(seed)+maxWords)
result = append(result, seed...)
for range maxWords {
start := len(result) - m.order
if start < 0 {
break
}
state := key(result[start:])
next, ok := m.NextWord(state)
if !ok {
break
}
result = append(result, next)
}
return result[len(seed):]
}
func tokenize(text string) []string {
var tokens []string
scanner := bufio.NewScanner(strings.NewReader(text))
scanner.Split(bufio.ScanWords)
for scanner.Scan() {
tokens = append(tokens, strings.ToLower(scanner.Text()))
}
return tokens
}
func main() {
corpus, _ := os.ReadFile("data/train.txt")
tokens := tokenize(string(corpus))
mc := NewMarkovChain(2)
mc.Train(tokens)
seed := []string{"the", "model"}
generated := mc.Generate(seed, 50)
fmt.Println(strings.Join(append(seed, generated...), " "))
}
Com um corpus de uns poucos megabytes de texto em inglês, a saída pode ser algo assim:
1
2
3
4
5
the model is trained on a large dataset of text that contains
the information we need to process in parallel with the other
components the model is not able to handle the long-range
dependencies that appear in natural language the model is
trained on a large dataset of text that contains the
Repare: localmente cada par de palavras parece plausível, mas em 20 tokens o texto já está girando em ciclos. O modelo não tem noção de que está repetindo, porque ele não tem memória além das últimas duas palavras.
N-gramas e a ordem da cadeia
A escolha de ordem define o equilíbrio entre coerência local e cobertura de dados.
O problema da esparsidade
Com um vocabulário de 50.000 palavras:
1
2
3
// Ordem 1: ~50k estados possíveis
// Ordem 2: ~50k² estados -> esparso com corpora normais
// Ordem 3: ~50k³ estados -> quase tudo não visto
Calculando:
- Ordem 1: 50.000 estados. Cobrível com poucos megabytes de texto.
- Ordem 2: 2,5 bilhões de estados possíveis. Um corpus de 1GB começa a cobrir uma fração razoável.
- Ordem 3: 125 trilhões de estados possíveis. Nenhum corpus real chega perto de cobrir isso.
A maioria dos trigramas que você encontra em texto novo nunca apareceu no treinamento. O modelo simplesmente não sabe o que fazer e para de gerar.
Comparando na prática
Vamos treinar cadeias de diferentes ordens sobre o mesmo corpus e contar quantos estados únicos cada uma aprende:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import (
"fmt"
"os"
)
func main() {
corpus, _ := os.ReadFile("data/train.txt")
tokens := tokenize(string(corpus))
for _, order := range []int{1, 2, 3} {
mc := NewMarkovChain(order)
mc.Train(tokens)
fmt.Printf("Ordem %d: %d estados únicos\n", order, len(mc.transitions))
}
}
Saída típica com 10MB de texto:
1
2
3
Ordem 1: 48.231 estados únicos
Ordem 2: 892.041 estados únicos
Ordem 3: 2.847.193 estados únicos
Ordem 3 já tem quase 3 milhões de estados a partir de 10MB. E a maior parte deles foi vista apenas uma vez, o que significa que as probabilidades de transição são baseadas em uma única observação. Isso não é estatístico: é memorização de exemplos específicos.
Elevar a ordem além de 3 ou 4 em textos normais produz resultados que parecem muito coerentes localmente porque o modelo está, na prática, reproduzindo trechos inteiros do corpus de treinamento.
O limite fundamental da abordagem local
A propriedade de Markov é ao mesmo tempo a força e o problema do modelo. Ela torna o cálculo tratável, mas corta exatamente o tipo de dependência que a linguagem natural precisa.
Dependências de longo alcance
Considere estas frases:
1
2
"O gato que perseguiu o rato estava com fome."
"Os gatos que perseguiram os ratos estavam com fome."
No primeiro caso, o verbo “estava” precisa concordar com “gato”, que aparece 5 tokens antes. No segundo, “estavam” precisa concordar com “gatos”, que aparece 5 tokens antes.
Uma cadeia de ordem 2 vê apenas ("ratos", "estava") ou ("ratos", "estavam") e precisa escolher. Sem acesso ao sujeito real da oração, não tem como fazer a escolha certa de forma sistemática.
Exemplos ainda mais longos:
1
2
"O cientista que desenvolveu a vacina que acabou com a doença que
matou milhares de pessoas na década passada recebeu o prêmio."
O verbo “recebeu” precisa concordar com “cientista”, que está 20 tokens atrás. Uma cadeia de Markov de qualquer ordem razoável não chega lá.
Pronomes e referências
Considere:
1
"Maria foi ao mercado. Ela comprou frutas."
O pronome “ela” refere-se a “Maria”, que está na sentença anterior. Uma cadeia de Markov de ordem 2 que vê ("Ela", "comprou") não sabe quem é “ela”. Não tem como saber, porque a informação está fora da janela.
Em textos longos, pronomes podem se referir a entidades mencionadas parágrafos atrás. O modelo simplesmente ignora toda essa estrutura.
Intenção narrativa
1
"It was the best of times, it was the worst of times"
A repetição estrutural de Dickens existe por uma razão narrativa. Uma Cadeia de Markov pode aprender que ("was", "the") leva a ("best", "of") ou ("worst", "of"), mas não entende que as duas estruturas coexistem porque o autor está construindo um contraste deliberado.
O modelo não tem representação de intenção, tema ou estrutura narrativa. Ele só tem contagens de coocorrência local.
Perplexidade: medindo o quanto o modelo está perdido
Como comparar objetivamente modelos de linguagem? A métrica padrão é a perplexidade.
A perplexidade mede, em média, quantas opções igualmente prováveis o modelo considera a cada passo. Menor é melhor.
Definição formal:
1
2
3
4
PP = exp(H)
onde H é a entropia cruzada média por token:
H = -(1/N) * Σ log P(token_i | contexto_i)
Valores de referência:
- Inglês a nível humano: ~20-30 perplexidade em texto típico
- Cadeia de Markov de ordem 2 bem treinada: 100-200 em dados de teste
- GPT-2 (2019): ~35 no conjunto WikiText-103
- GPT-4: abaixo de 10 em benchmarks padrão
Implementação em Go:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import "math"
func Perplexity(mc *MarkovChain, tokens []string) float64 {
var logProb float64
var count int
for i := 0; i+mc.order < len(tokens); i++ {
state := key(tokens[i : i+mc.order])
next := tokens[i+mc.order]
total := mc.totals[state]
if total == 0 {
logProb += -10 // penalidade para estado desconhecido
} else {
p := float64(mc.transitions[state][next]) / float64(total)
if p == 0 {
p = 1e-10 // suavização para evitar log(0)
}
logProb += math.Log(p)
}
count++
}
return math.Exp(-logProb / float64(count))
}
O ponto importante: a perplexidade é calculada sobre dados que o modelo não viu no treinamento. Calcular sobre os dados de treinamento não diz nada: o modelo pode simplesmente memorizar os dados e ter perplexidade 1.
Para usar:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
func main() {
corpus, _ := os.ReadFile("data/train.txt")
testData, _ := os.ReadFile("data/test.txt")
trainTokens := tokenize(string(corpus))
testTokens := tokenize(string(testData))
for _, order := range []int{1, 2, 3} {
mc := NewMarkovChain(order)
mc.Train(trainTokens)
pp := Perplexity(mc, testTokens)
fmt.Printf("Ordem %d: perplexidade = %.2f\n", order, pp)
}
}
Saída típica:
1
2
3
Ordem 1: perplexidade = 892.41
Ordem 2: perplexidade = 312.18
Ordem 3: perplexidade = 187.93
Ordens maiores têm perplexidade menor no texto de teste, mas apenas até um certo ponto. Com ordem 4 ou 5 a perplexidade começa a subir de novo porque a esparsidade dos dados domina.
Backoff e suavização
Pesquisadores de NLP passaram décadas tentando corrigir os problemas das cadeias de Markov. Duas técnicas merecem menção.
Suavização de Laplace
O problema mais simples: estados que nunca foram vistos têm probabilidade zero, o que quebra o cálculo de entropia cruzada. A suavização de Laplace adiciona 1 a todas as contagens, eliminando os zeros:
1
2
3
4
5
6
// Em vez de:
p := float64(mc.transitions[state][next]) / float64(total)
// Com suavização de Laplace (add-1):
vocabSize := float64(len(allTokens))
p := (float64(mc.transitions[state][next]) + 1) / (float64(total) + vocabSize)
Isso resolve o problema de probabilidade zero, mas distorce as estimativas para estados raros. Se um estado foi visto apenas 3 vezes, adicionar 1 a cada alternativa do vocabulário (50.000 palavras) produz probabilidades completamente erradas.
Backoff (Katz e Kneser-Ney)
Uma ideia mais elegante: quando o modelo não encontra um estado de ordem N, ele “recua” para um estado de ordem N-1.
Se o trigrama ("comeu", "o", "peixe") nunca foi visto, tente o bigrama ("o", "peixe"). Se esse também não foi visto, tente o unigrama ("peixe"). Se nada funcionar, distribua a probabilidade uniformemente sobre o vocabulário.
O Kneser-Ney é a versão mais sofisticada desse backoff e foi por muito tempo o estado da arte em modelos de linguagem baseados em n-gramas. Ele reduz a perplexidade em 20-30% em relação a Katz simples.
Mesmo assim, essas técnicas apenas atenuam os sintomas. O problema fundamental, a incapacidade de modelar dependências de longo alcance, permanece.
O que vem a seguir
A falha da Cadeia de Markov é instrutiva: ela mostra exatamente que tipo de capacidade precisamos construir.
Um modelo de linguagem útil precisa:
- Representar tokens como vetores densos, não símbolos discretos (já construímos isso no post 2).
- Ter alguma forma de memória que não seja apenas os últimos N tokens.
- Aprender quais partes do contexto são relevantes para prever o próximo token, em vez de tratar todos os tokens do contexto da mesma forma.
O ponto 3 é o que a atenção resolve. Mas antes de chegar lá, precisamos entender os blocos básicos de construção: um neurônio, depois uma rede feedforward, depois gradiente descendente para aprender os pesos sem tabelas de contagem manuais.
No próximo post vamos construir o primeiro neurônio em Go, implementar uma rede feedforward simples, e mostrar como o gradiente descendente encontra os pesos certos. Esse é o ponto de inflexão da série: de contagens para aprendizado de representações.
Referências
- Andrei Markov - Extensão da Lei dos Grandes Números (1906)
- Shannon, Claude - A Mathematical Theory of Communication (1948)
- Jurafsky & Martin - Speech and Language Processing (3a ed., grátis online)
- Kneser-Ney Smoothing - explicação detalhada
- NLTK - N-gramas em Python (referência conceitual)
- Repositório da série LLM do Zero